 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-Atom GPCR-Ligand Simulation via Residual Isometric Latent Flow
Feb 03, 2026G-protein-coupled receptors (GPCRs), primary targets for over one-third of approved therapeutics, rely on intricate conformational transitions to transduce signals. While Molecular Dynamics (MD) is essential for elucidating this transduction process, particularly within ligand-bound complexes, conventional all-atom MD simulation is computationally prohibitive. In this paper, we introduce GPCRLMD, a deep generative framework for efficient all-atom GPCR-ligand simulation.GPCRLMD employs a Harmonic-Prior Variational Autoencoder (HP-VAE) to first map the complex into a regularized isometric latent space, preserving geometric topology via physics-informed constraints. Within this latent space, a Residual Latent Flow samples evolution trajectories, which are subsequently decoded back to atomic coordinates. By capturing temporal dynamics via relative displacements anchored to the initial structure, this residual mechanism effectively decouples static topology from dynamic fluctuations. Experimental results demonstrate that GPCRLMD achieves state-of-the-art performance in GPCR-ligand dynamics simulation, faithfully reproducing thermodynamic observables and critical ligand-receptor interactions.
Enhanced Sampling, Public Dataset and Generative Model for Drug-Protein Dissociation Dynamics
Apr 25, 2025Drug-protein binding and dissociation dynamics are fundamental to understanding molecular interactions in biological systems. While many tools for drug-protein interaction studies have emerged, especially artificial intelligence (AI)-based generative models, predictive tools on binding/dissociation kinetics and dynamics are still limited. We propose a novel research paradigm that combines molecular dynamics (MD) simulations, enhanced sampling, and AI generative models to address this issue. We propose an enhanced sampling strategy to efficiently implement the drug-protein dissociation process in MD simulations and estimate the free energy surface (FES). We constructed a program pipeline of MD simulations based on this sampling strategy, thus generating a dataset including 26,612 drug-protein dissociation trajectories containing about 13 million frames. We named this dissociation dynamics dataset DD-13M and used it to train a deep equivariant generative model UnbindingFlow, which can generate collision-free dissociation trajectories. The DD-13M database and UnbindingFlow model represent a significant advancement in computational structural biology, and we anticipate its broad applicability in machine learning studies of drug-protein interactions. Our ongoing efforts focus on expanding this methodology to encompass a broader spectrum of drug-protein complexes and exploring novel applications in pathway prediction.
Graph Augmentation for Cross Graph Domain Generalization
Feb 25, 2025Cross-graph node classification, utilizing the abundant labeled nodes from one graph to help classify unlabeled nodes in another graph, can be viewed as a domain generalization problem of graph neural networks (GNNs) due to the structure shift commonly appearing among various graphs. Nevertheless, current endeavors for cross-graph node classification mainly focus on model training. Data augmentation approaches, a simple and easy-to-implement domain generalization technique, remain under-explored. In this paper, we develop a new graph structure augmentation for the crossgraph domain generalization problem. Specifically, low-weight edgedropping is applied to remove potential noise edges that may hinder the generalization ability of GNNs, stimulating the GNNs to capture the essential invariant information underlying different structures. Meanwhile, clustering-based edge-adding is proposed to generate invariant structures based on the node features from the same distribution. Consequently, with these augmentation techniques, the GNNs can maintain the domain invariant structure information that can improve the generalization ability. The experiments on out-ofdistribution citation network datasets verify our method achieves state-of-the-art performance among conventional augmentations.
Efficient Antibody Structure Refinement Using Energy-Guided SE(3) Flow Matching
Oct 22, 2024



Antibodies are proteins produced by the immune system that recognize and bind to specific antigens, and their 3D structures are crucial for understanding their binding mechanism and designing therapeutic interventions. The specificity of antibody-antigen binding predominantly depends on the complementarity-determining regions (CDR) within antibodies. Despite recent advancements in antibody structure prediction, the quality of predicted CDRs remains suboptimal. In this paper, we develop a novel antibody structure refinement method termed FlowAB based on energy-guided flow matching. FlowAB adopts the powerful deep generative method SE(3) flow matching and simultaneously incorporates important physical prior knowledge into the flow model to guide the generation process. The extensive experiments demonstrate that FlowAB can significantly improve the antibody CDR structures. It achieves new state-of-the-art performance on the antibody structure prediction task when used in conjunction with an appropriate prior model while incurring only marginal computational overhead. This advantage makes FlowAB a practical tool in antibody engineering.
SubGDiff: A Subgraph Diffusion Model to Improve Molecular Representation Learning
May 09, 2024Molecular representation learning has shown great success in advancing AI-based drug discovery. The core of many recent works is based on the fact that the 3D geometric structure of molecules provides essential information about their physical and chemical characteristics. Recently, denoising diffusion probabilistic models have achieved impressive performance in 3D molecular representation learning. However, most existing molecular diffusion models treat each atom as an independent entity, overlooking the dependency among atoms within the molecular substructures. This paper introduces a novel approach that enhances molecular representation learning by incorporating substructural information within the diffusion process. We propose a novel diffusion model termed SubGDiff for involving the molecular subgraph information in diffusion. Specifically, SubGDiff adopts three vital techniques: i) subgraph prediction, ii) expectation state, and iii) k-step same subgraph diffusion, to enhance the perception of molecular substructure in the denoising network. Experimentally, extensive downstream tasks demonstrate the superior performance of our approach. The code is available at https://github.com/youjibiying/SubGDiff.
A Simple Hypergraph Kernel Convolution based on Discounted Markov Diffusion Process
Oct 30, 2022



Kernels on discrete structures evaluate pairwise similarities between objects which capture semantics and inherent topology information. Existing kernels on discrete structures are only developed by topology information(such as adjacency matrix of graphs), without considering original attributes of objects. This paper proposes a two-phase paradigm to aggregate comprehensive information on discrete structures leading to a Discount Markov Diffusion Learnable Kernel (DMDLK). Specifically, based on the underlying projection of DMDLK, we design a Simple Hypergraph Kernel Convolution (SHKC) for hidden representation of vertices. SHKC can adjust diffusion steps rather than stacking convolution layers to aggregate information from long-range neighborhoods which prevents over-smoothing issues of existing hypergraph convolutions. Moreover, we utilize the uniform stability bound theorem in transductive learning to analyze critical factors for the effectiveness and generalization ability of SHKC from a theoretical perspective. The experimental results on several benchmark datasets for node classification tasks verified the superior performance of SHKC over state-of-the-art methods.
GraphTTA: Test Time Adaptation on Graph Neural Networks
Aug 19, 2022
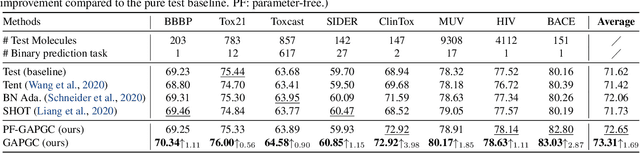
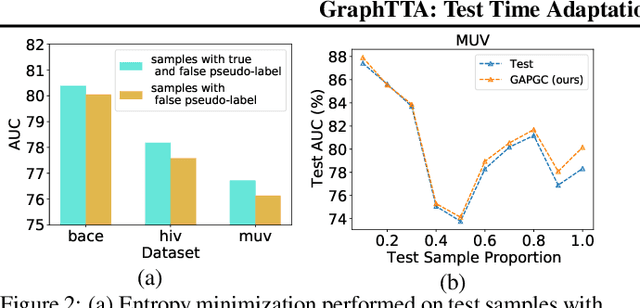

Recently, test time adaptation (TTA) has attracted increasing attention due to its power of handling the distribution shift issue in the real world. Unlike what has been developed for convolutional neural networks (CNNs) for image data, TTA is less explored for Graph Neural Networks (GNNs). There is still a lack of efficient algorithms tailored for graphs with irregular structures. In this paper, we present a novel test time adaptation strategy named Graph Adversarial Pseudo Group Contrast (GAPGC), for graph neural networks TTA, to better adapt to the Out Of Distribution (OOD) test data. Specifically, GAPGC employs a contrastive learning variant as a self-supervised task during TTA, equipped with Adversarial Learnable Augmenter and Group Pseudo-Positive Samples to enhance the relevance between the self-supervised task and the main task, boosting the performance of the main task. Furthermore, we provide theoretical evidence that GAPGC can extract minimal sufficient information for the main task from information theory perspective. Extensive experiments on molecular scaffold OOD dataset demonstrated that the proposed approach achieves state-of-the-art performance on GNNs.
Hypergraph Convolutional Networks via Equivalency between Hypergraphs and Undirected Graphs
Apr 06, 2022
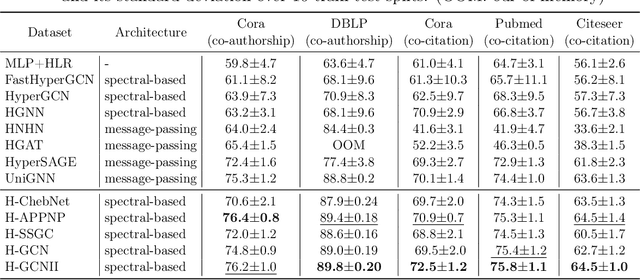

As a powerful tool for modeling complex relationships, hypergraphs are gaining popularity from the graph learning community. However, commonly used frameworks in deep hypergraph learning focus on hypergraphs with \textit{edge-independent vertex weights}(EIVWs), without considering hypergraphs with \textit{edge-dependent vertex weights} (EDVWs) that have more modeling power. To compensate for this, in this paper, we present General Hypergraph Spectral Convolution(GHSC), a general learning framework that not only can handle EDVW and EIVW hypergraphs, but more importantly, enables theoretically explicitly utilizing the existing powerful Graph Convolutional Neural Networks (GCNNs) such that largely ease the design of Hypergraph Neural Networks. In this framework, the graph Laplacian of the given undirected GCNNs is replaced with a unified hypergraph Laplacian that incorporates vertex weight information from a random walk perspective by equating our defined generalized hypergraphs with simple undirected graphs. Extensive experiments from various domains including social network analysis, visual objective classification, protein learning demonstrate that the proposed framework can achieve state-of-the-art performance.
Preventing Over-Smoothing for Hypergraph Neural Networks
Mar 31, 2022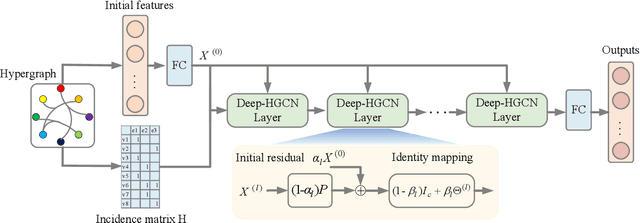
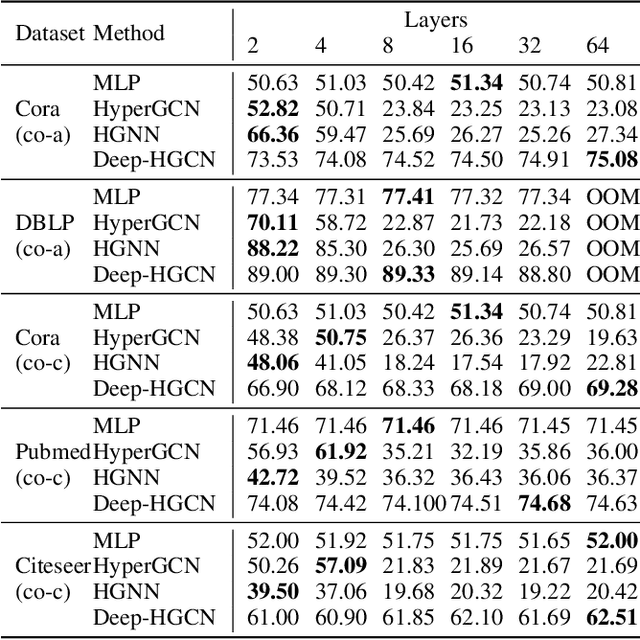
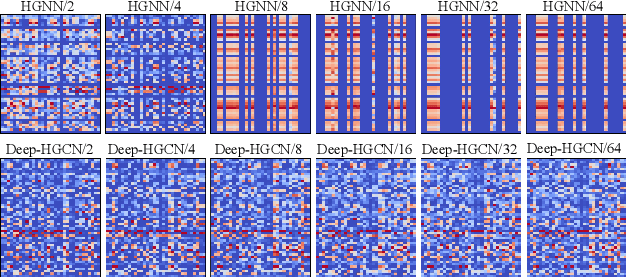
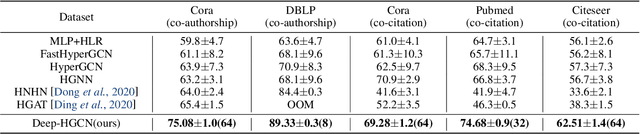
In recent years, hypergraph learning has attracted great attention due to its capacity in representing complex and high-order relationships. However, current neural network approaches designed for hypergraphs are mostly shallow, thus limiting their ability to extract information from high-order neighbors. In this paper, we show both theoretically and empirically, that the performance of hypergraph neural networks does not improve as the number of layers increases, which is known as the over-smoothing problem. To tackle this issue, we develop a new deep hypergraph convolutional network called Deep-HGCN, which can maintain the heterogeneity of node representation in deep layers. Specifically, we prove that a $k$-layer Deep-HGCN simulates a polynomial filter of order $k$ with arbitrary coefficients, which can relieve the problem of over-smoothing. Experimental results on various datasets demonstrate the superior performance of the proposed model comparing to the state-of-the-art hypergraph learning approaches.
Fine-Tuning Graph Neural Networks via Graph Topology induced Optimal Transport
Mar 20, 2022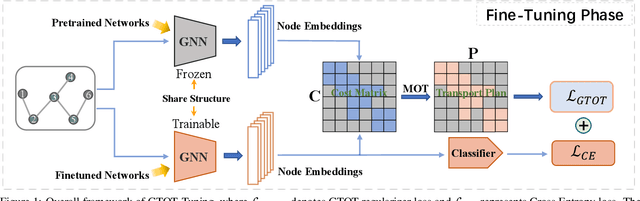
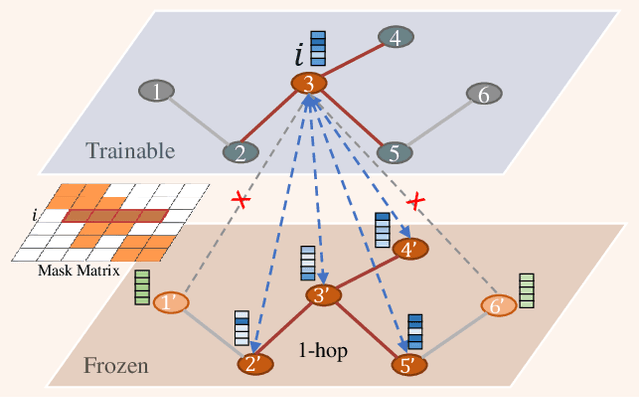
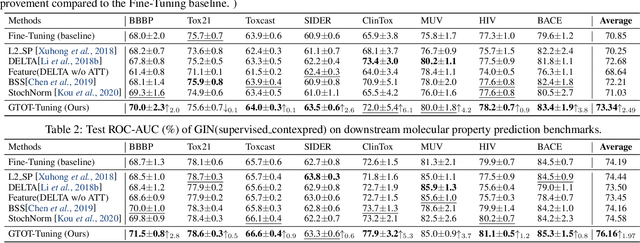
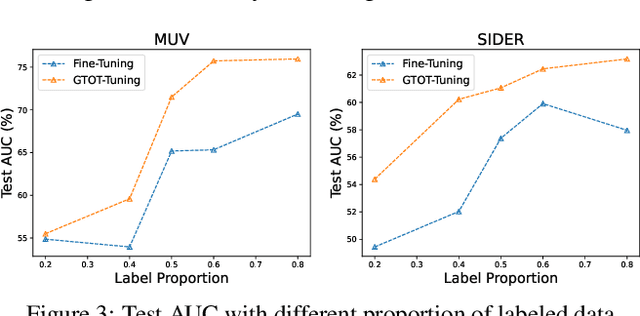
Recently, the pretrain-finetuning paradigm has attracted tons of attention in graph learning community due to its power of alleviating the lack of labels problem in many real-world applications. Current studies use existing techniques, such as weight constraint, representation constraint, which are derived from images or text data, to transfer the invariant knowledge from the pre-train stage to fine-tuning stage. However, these methods failed to preserve invariances from graph structure and Graph Neural Network (GNN) style models. In this paper, we present a novel optimal transport-based fine-tuning framework called GTOT-Tuning, namely, Graph Topology induced Optimal Transport fine-Tuning, for GNN style backbones. GTOT-Tuning is required to utilize the property of graph data to enhance the preservation of representation produced by fine-tuned networks. Toward this goal, we formulate graph local knowledge transfer as an Optimal Transport (OT) problem with a structural prior and construct the GTOT regularizer to constrain the fine-tuned model behaviors. By using the adjacency relationship amongst nodes, the GTOT regularizer achieves node-level optimal transport procedures and reduces redundant transport procedures, resulting in efficient knowledge transfer from the pre-trained models. We evaluate GTOT-Tuning on eight downstream tasks with various GNN backbones and demonstrate that it achieves state-of-the-art fine-tuning performance for GNNs.